
Interactive Democracy
After having looked at two economics-focused papers, its time for a change! Let's take a deeper look at how computers can aid us to make better democratic decisions.
Democratic systems consist of many different overlapping concepts: from voting systems, to discussion fora, to modeling proper balances of power. Today's paper does not present a new formal description of "interactive democracy" but is rather a literature overview of several of these concepts. The field is a big one with lots of avenues to explore:
When designing a platform for interactive collective decision
making, there are lots of design decisions to be made, regarding, for example, issue selection (which issues are considered?), option generation (which options are on the ballot?), interaction opportunities (how is deliberation and delegation organized?), ballot structure (in which format can participants express their preferences?), and aggregation methods (which method is used to tally the votes?).
In this article, I argue that concepts and techniques from the
multiagent systems literature—particularly those dealing with preferences and their aggregation—should be employed
Besides theoretical issues, the author also looks at practical barriers towards real-world implementation. As it covers a lot of ground (citing over 65 sources, it is a treasure trove!), I'll focus on highlighting just a few of the interesting insights, especially those offered through the use of computational methods.
Delegative voting
In recent years, a radical adjustment to voting systems has risen in popularity: delegative voting. Such an adjustment would enable voters to delegate their voting power to others. In proxy voting you can only delegate their own vote whereas in liquid democracy you can also delegate the votes which were delegated to you. Delegative voting is powerful because it blurs the boundary between a representative democracy and direct democracy, which would otherwise be seen as opposites. A representative democracy is attractive because you can elect people to specialize in governing society, whilst direct democracy is attractive because we get more accurate information about people's preferences. This is a method which can break through the democratic reform trilemma. However, there are some difficulties which need to be overcome:
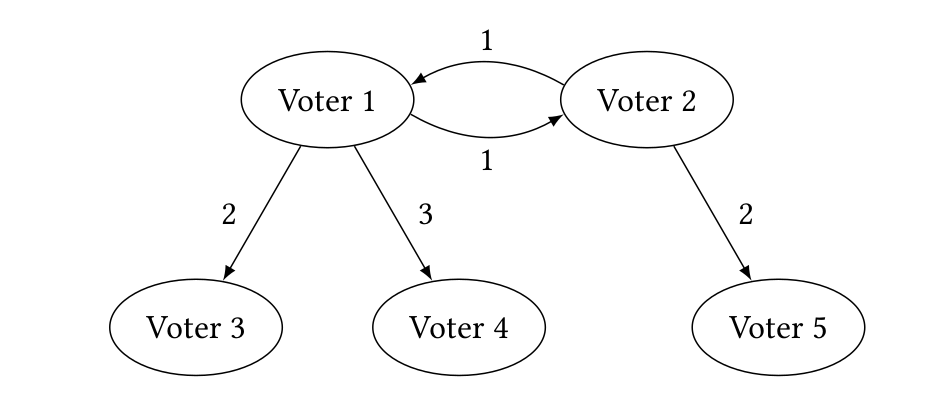
in order to successfully implement a delegative voting infrastructure, one has to think about potential problems such as: (1) delegation cycles (voter 1 delegates her vote to voter 2, who delegates to voter 3, who delegates back to voter 1), (2) abstentions (what if one delegates to somebody who abstains from voting?), and (3) inconsistent outcomes (what if different delegations for different issues lead to a globally incompatible set of decisions?).
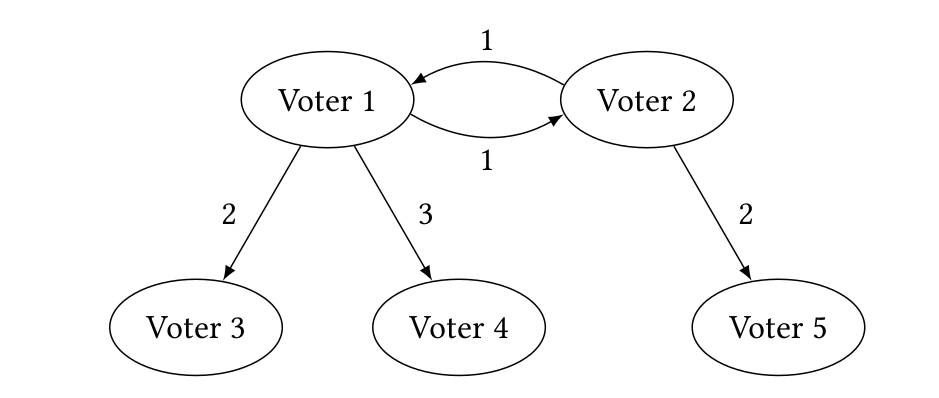
Problems (1) and (2) can potentially be resolved by asking from each voter to specify a ranked list of delegations. However, finding a single optimal set of delegations in the presence of abstentions and cycles is hard. As before on Equilibria Club, randomness comes to the rescue!
One possibility to resolve situations like the one just described
consists in employing a Markov chain approach. Let ε ∈ (0, 1) and
consider a random walk on the delegation graph (e.g., the graph
in Figure 1) that starts at some fixed delegating voter and follows
delegation edges as follows: With probability proportional to 1, go
to the most preferred delegate of the current voter; with probability proportional to ε, go to the second most preferred delegate; with probability proportional to ε^2 , go to the third most preferred delegate; and so on. The idea behind this definition is that we will almost always delegate to the most preferred delegate; if this results in a delegation cycle, however, we will eventually delegate elsewhere to leave the cycle. When the random walk gets stuck at an abstaining voter, it is restarted. When it reaches a voter that actually voted, we have found the voter to which the vote is delegated. This defines a randomized way to resolve delegation cycles that also takes care of
abstentions.
But good results can also be achieved in a simpler way. Instead of using computationally heavy algorithms, voters can also just:
specify “default” votes that are used to overrule delegation decisions should the latter lead to delegation cycles or abstentions.
Throughout today's paper, a range of interesting extensions of voting systems are mentioned which one can only dream of happening efficiently in a governmental context, for example: voting or delegating based on issues and allowing voters to submit options to the ballot. Besides the practical roadblocks which are in the way of implementing such extensions, all of this flexibility is also not free in a theoretical world without friction:
In general, there appears to be a tradeoff between flexible and
fine-grained delegation possibilities on the one side and increased
potential of inconsistent (or underspecified) outcomes on the other side. In this context, it will be interesting to explore generalizations of delegative voting such as statement voting [65].
Properties of Aggregation Functions
After opinions are formed, ballots are created and votes are delegated and cast, the final step in the voting process is to aggregate them. As with the other topics, lots of design challenges await:
One example of such a property is independence of clones. Two
alternatives are said to be clones if they are ranked consecutively
by all voters. [...] Independence of clones is a very desirable property because it eliminates incentives to strategically introduce new alternatives. It is particularly important in the context of online decision platforms, where all participants can nominate alternatives (see Section 3.1) and thus the existence
of multiple very similar alternatives is very likely.
When there is a finite set of alternatives and the preferences of voters can be indicated as rank-orderings over this set (voter 1 prefers options A, B and C in that order, voter 2 prefers options B, A and C in that order, etc.) aggregation is not that hard. However, sometimes the space of alternatives has some combinatorial structure. Think for example of participatory budgeting (voter 1 prefers that 10, 11 and 14 Bitcoin are allocated to options A, B and C respectively, voter 2 prefers that 15, 2 and 3 Bitcoin are allocated to options A, B and C respectively). In the latter scenario, you cannot simply add up the budgets as that would quickly raise the government deficit! Moreover, preferences can be indicated in many different formats which would all have different trade-offs: do voters get a hypothetical budget to allocate? Are they allowed to indicate a negative budget for options they really dislike?
Each preference format presents a tradeoff between expressive power (does the format allow to express fine-grained preferences?), succinctness (can preferences be represented compactly?), and aggregatability (does the preference format allow for a computationally efficient and axiomatically desirable aggregation mechanism?), among other things.
As with many of the mechanisms discussed so far, these questions may only start to play an important role in a highly automated environment (think Decentralized Autonomous Organizations) and less in your local government. Moreover, with such a large design space to consider, there may be a Pareto rule at play here, where those implementing voting systems should start by only taking into account a few key questions. Lots of further extensions are possible, some of which I will dive deeper into in future editions of Equilibria Club!
in the future it is conceivable that reputation systems [55] and recommender systems [56, 57] are employed to help voters decide where to delegate their vote (or how to vote), argumentation frameworks [27, 28] are employed to structure deliberation processes, and logical frameworks like CP-nets [12] are employed to give voters more flexibility when expressing their preferences.